Sobre fluxos de trabalho
Um fluxo de trabalho é um processo automatizado configurável que executa um ou mais trabalhos. Os fluxos de trabalho são definidos por um arquivo YAML verificado no seu repositório e será executado quando acionado por um evento no repositório, ou eles podem ser acionados manualmente ou de acordo com um cronograma definido.
Os fluxos de trabalho são definidos no diretório .github/workflows em um repositório. Um repositório pode ter vários fluxos de trabalho, cada um dos quais pode executar um conjunto diferente de tarefas. Por exemplo, você pode ter um fluxo de trabalho para criar e testar pull requests, outro fluxo de trabalho para implantar seu aplicativo toda vez que uma versão for criada, e outro fluxo de trabalho que adiciona uma etiqueta toda vez que alguém abre um novo problema.
Noções básicas do fluxo de trabalho
Um fluxo de trabalho precisa conter os seguintes componentes básicos:
- Um ou mais eventos que acionarão o fluxo de trabalho.
- Um ou mais trabalhos, cada um deles será executado em um computador executor e executará uma série de uma ou mais etapas.
- Cada etapa pode executar um script que você define ou executa uma ação, que é uma extensão reutilizável que pode simplificar seu fluxo de trabalho.
Para obter mais informações sobre esses componentes básicos, confira "Entendendo o GitHub Actions".

Acionando um fluxo de trabalho
Os acionadores de fluxo de trabalho são eventos que fazem com que um fluxo de trabalho seja executado. Esses eventos podem ser:
- Eventos que ocorrem no repositório do fluxo de trabalho
- Eventos que ocorrem fora do GitHub e que disparam um evento
repository_dispatchno GitHub - Horários agendados
- Manual
Por exemplo, você pode configurar o fluxo de trabalho para executar quando um push é feito no branch padrão do seu repositório, quando uma versão é criada, ou quando um problema é aberto.
Para obter mais informações, confira "Acionando um fluxo de trabalho, e para uma lista completa de eventos, confira "Eventos que disparam fluxos de trabalho".
Sintaxe de fluxo de trabalho
O fluxo de trabalho é definido usando YAML. Para obter a referência completa da sintaxe do YAML para a criação de fluxos de trabalho, confira "Sintaxe de fluxo de trabalho para o GitHub Actions".
Criar um exemplo de fluxo de trabalho
GitHub Actions usa a sintaxe do YAML para definir o fluxo de trabalho. Cada fluxo de trabalho é armazenado como um arquivo YAML separado no seu repositório de código, em um diretório chamado .github/workflows.
Você pode criar um exemplo de fluxo de trabalho no repositório que aciona automaticamente uma série de comandos sempre que o código for carregado. Nesse fluxo de trabalho, GitHub Actions verifica o código enviado, instala a estrutura de teste bats e executa um comando básico para gerar a versão bats:bats -v.
-
No repositório, crie o diretório
.github/workflows/para armazenar os arquivos de fluxo de trabalho. -
No diretório
.github/workflows/, crie um arquivo chamadolearn-github-actions.ymle adicione o código a seguir.YAML name: learn-github-actions run-name: ${{ github.actor }} is learning GitHub Actions on: [push] jobs: check-bats-version: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - uses: actions/setup-node@v4 with: node-version: '20' - run: npm install -g bats - run: bats -vname: learn-github-actions run-name: ${{ github.actor }} is learning GitHub Actions on: [push] jobs: check-bats-version: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - uses: actions/setup-node@v4 with: node-version: '20' - run: npm install -g bats - run: bats -v -
Faça commit dessas alterações e faça push para o seu repositório do GitHub.
Seu novo arquivo de fluxo de trabalho de GitHub Actions agora está instalado no seu repositório e será executado automaticamente toda vez que alguém fizer push de uma alteração no repositório. Para conferir os detalhes sobre o histórico de execução de um fluxo de trabalho, confira "Exibir a atividade de uma execução de fluxo de trabalho".
Entender o arquivo de fluxo de trabalho
Para ajudar você a entender como a sintaxe de YAML é usada para criar um arquivo de fluxo de trabalho, esta seção explica cada linha do exemplo Introdução:
# Optional - The name of the workflow as it will appear in the "Actions" tab of the GitHub repository. If this field is omitted, the name of the workflow file will be used instead.
name: learn-github-actions
# Optional - The name for workflow runs generated from the workflow, which will appear in the list of workflow runs on your repository's "Actions" tab. This example uses an expression with the `github` context to display the username of the actor that triggered the workflow run. For more information, see "[AUTOTITLE](/actions/using-workflows/workflow-syntax-for-github-actions#run-name)."
run-name: ${{ github.actor }} is learning GitHub Actions
# Specifies the trigger for this workflow. This example uses the `push` event, so a workflow run is triggered every time someone pushes a change to the repository or merges a pull request. This is triggered by a push to every branch; for examples of syntax that runs only on pushes to specific branches, paths, or tags, see "[AUTOTITLE](/actions/reference/workflow-syntax-for-github-actions#onpushpull_requestpull_request_targetpathspaths-ignore)."
on: [push]
# Groups together all the jobs that run in the `learn-github-actions` workflow.
jobs:
# Defines a job named `check-bats-version`. The child keys will define properties of the job.
check-bats-version:
# Configures the job to run on the latest version of an Ubuntu Linux runner. This means that the job will execute on a fresh virtual machine hosted by GitHub. For syntax examples using other runners, see "[AUTOTITLE](/actions/reference/workflow-syntax-for-github-actions#jobsjob_idruns-on)"
runs-on: ubuntu-latest
# Groups together all the steps that run in the `check-bats-version` job. Each item nested under this section is a separate action or shell script.
steps:
# The `uses` keyword specifies that this step will run `v4` of the `actions/checkout` action. This is an action that checks out your repository onto the runner, allowing you to run scripts or other actions against your code (such as build and test tools). You should use the checkout action any time your workflow will use the repository's code.
- uses: actions/checkout@v4
# This step uses the `actions/setup-node@v4` action to install the specified version of the Node.js. (This example uses version 14.) This puts both the `node` and `npm` commands in your `PATH`.
- uses: actions/setup-node@v4
with:
node-version: '20'
# The `run` keyword tells the job to execute a command on the runner. In this case, you are using `npm` to install the `bats` software testing package.
- run: npm install -g bats
# Finally, you'll run the `bats` command with a parameter that outputs the software version.
- run: bats -v
name: learn-github-actionsOptional - The name of the workflow as it will appear in the "Actions" tab of the GitHub repository. If this field is omitted, the name of the workflow file will be used instead.
run-name: ${{ github.actor }} is learning GitHub ActionsOptional - The name for workflow runs generated from the workflow, which will appear in the list of workflow runs on your repository's "Actions" tab. This example uses an expression with the github context to display the username of the actor that triggered the workflow run. For more information, see "Sintaxe de fluxo de trabalho para o GitHub Actions."
on: [push]Specifies the trigger for this workflow. This example uses the push event, so a workflow run is triggered every time someone pushes a change to the repository or merges a pull request. This is triggered by a push to every branch; for examples of syntax that runs only on pushes to specific branches, paths, or tags, see "Sintaxe de fluxo de trabalho para o GitHub Actions."
jobs:Groups together all the jobs that run in the learn-github-actions workflow.
check-bats-version:Defines a job named check-bats-version. The child keys will define properties of the job.
runs-on: ubuntu-latestConfigures the job to run on the latest version of an Ubuntu Linux runner. This means that the job will execute on a fresh virtual machine hosted by GitHub. For syntax examples using other runners, see "Sintaxe de fluxo de trabalho para o GitHub Actions"
steps:Groups together all the steps that run in the check-bats-version job. Each item nested under this section is a separate action or shell script.
- uses: actions/checkout@v4The uses keyword specifies that this step will run v4 of the actions/checkout action. This is an action that checks out your repository onto the runner, allowing you to run scripts or other actions against your code (such as build and test tools). You should use the checkout action any time your workflow will use the repository's code.
- uses: actions/setup-node@v4
with:
node-version: '20'This step uses the actions/setup-node@v4 action to install the specified version of the Node.js. (This example uses version 14.) This puts both the node and npm commands in your PATH.
- run: npm install -g batsThe run keyword tells the job to execute a command on the runner. In this case, you are using npm to install the bats software testing package.
- run: bats -vFinally, you'll run the bats command with a parameter that outputs the software version.
# Optional - The name of the workflow as it will appear in the "Actions" tab of the GitHub repository. If this field is omitted, the name of the workflow file will be used instead.
name: learn-github-actions
# Optional - The name for workflow runs generated from the workflow, which will appear in the list of workflow runs on your repository's "Actions" tab. This example uses an expression with the `github` context to display the username of the actor that triggered the workflow run. For more information, see "[AUTOTITLE](/actions/using-workflows/workflow-syntax-for-github-actions#run-name)."
run-name: ${{ github.actor }} is learning GitHub Actions
# Specifies the trigger for this workflow. This example uses the `push` event, so a workflow run is triggered every time someone pushes a change to the repository or merges a pull request. This is triggered by a push to every branch; for examples of syntax that runs only on pushes to specific branches, paths, or tags, see "[AUTOTITLE](/actions/reference/workflow-syntax-for-github-actions#onpushpull_requestpull_request_targetpathspaths-ignore)."
on: [push]
# Groups together all the jobs that run in the `learn-github-actions` workflow.
jobs:
# Defines a job named `check-bats-version`. The child keys will define properties of the job.
check-bats-version:
# Configures the job to run on the latest version of an Ubuntu Linux runner. This means that the job will execute on a fresh virtual machine hosted by GitHub. For syntax examples using other runners, see "[AUTOTITLE](/actions/reference/workflow-syntax-for-github-actions#jobsjob_idruns-on)"
runs-on: ubuntu-latest
# Groups together all the steps that run in the `check-bats-version` job. Each item nested under this section is a separate action or shell script.
steps:
# The `uses` keyword specifies that this step will run `v4` of the `actions/checkout` action. This is an action that checks out your repository onto the runner, allowing you to run scripts or other actions against your code (such as build and test tools). You should use the checkout action any time your workflow will use the repository's code.
- uses: actions/checkout@v4
# This step uses the `actions/setup-node@v4` action to install the specified version of the Node.js. (This example uses version 14.) This puts both the `node` and `npm` commands in your `PATH`.
- uses: actions/setup-node@v4
with:
node-version: '20'
# The `run` keyword tells the job to execute a command on the runner. In this case, you are using `npm` to install the `bats` software testing package.
- run: npm install -g bats
# Finally, you'll run the `bats` command with a parameter that outputs the software version.
- run: bats -v
Visualizar o arquivo de fluxo de trabalho
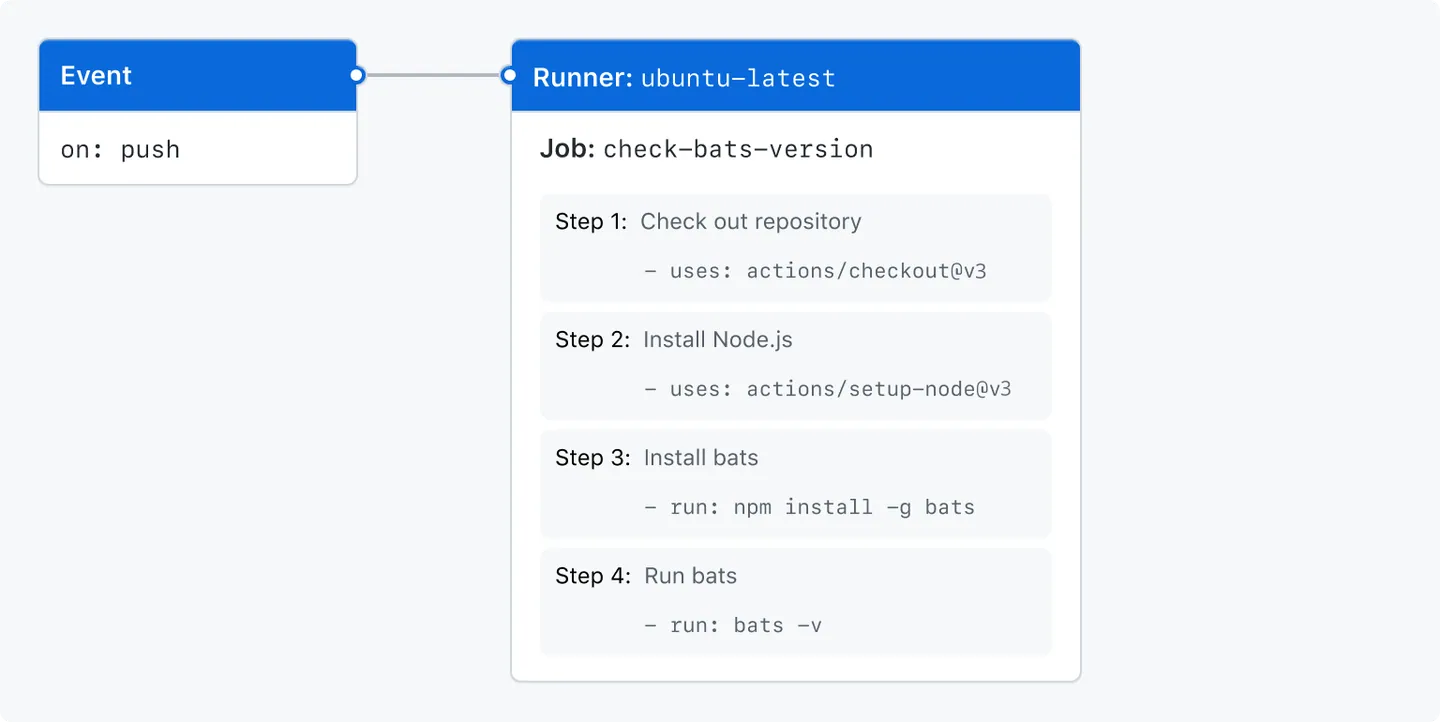
Neste diagrama, você pode ver o arquivo de fluxo de trabalho que acabou de criar e como os componentes de GitHub Actions estão organizados em uma hierarquia. Cada etapa executa uma única ação ou script do shell. As etapas 1 e 2 executam ações, enquanto as etapas 3 e 4 executam scripts de shell. Para encontrar mais ações predefinidas para seus fluxos de trabalho, confira "Procurar e personalizar ações".
Exibir a atividade para uma execução de fluxo de trabalho
Quando seu fluxo de trabalho é acionado, é criada uma execução de fluxo de trabalho que executa o fluxo de trabalho. Após o início de uma execução de fluxo de trabalho, você pode ver um gráfico de visualização do progresso da execução e visualizar a atividade de cada etapa em GitHub.
-
No GitHub.com, navegue até a página principal do repositório.
-
No nome do repositório, clique em Ações.

-
Na barra lateral esquerda, clique no fluxo de trabalho que deseja ver.
-
Na lista de execuções de fluxo de trabalho, clique no nome da execução para ver o resumo da execução do fluxo de trabalho.
-
Na barra lateral esquerda ou no grafo de visualização, clique no trabalho que deseja ver.
-
Para ver os resultados de uma etapa, clique na etapa.


Para obter mais informações sobre como gerenciar execuções de fluxo de trabalho, tais como executar novamente, cancelar ou excluir uma execução de fluxo de trabalho, confira "Gerenciar fluxos de trabalho".
Usando fluxos de trabalho iniciais
O GitHub fornece fluxos de trabalho iniciais pré-configurados que você pode personalizar para criar seu fluxo de trabalho de integração contínua. O GitHub analisa seu código e mostra os fluxos de trabalho iniciais de CI que podem ser úteis para seu repositório. Por exemplo, se o seu repositório contiver o código Node.js, você verá sugestões para projetos Node.js. Você pode usar fluxos de trabalho iniciais como ponto de partida para criar seu fluxo de trabalho personalizado ou usá-los no estado em que se encontram.
Navegue pela lista completa de fluxos de trabalho iniciais no repositório actions/starter-workflows.
Para obter mais informações sobre como usar e criar fluxos de trabalho iniciais, confira "Usando fluxos de trabalho iniciais" e "Criando fluxos de trabalho iniciais para sua organização".
Recursos avançados de fluxo de trabalho
Esta seção descreve brevemente alguns dos recursos avançados de GitHub Actions que ajudam a criar fluxos de trabalho mais complexos.
Armazenar segredos
Se os fluxos de trabalho usarem dados confidenciais, como senhas ou certificados, salve-os no GitHub como segredos e use-os nos seus fluxos de trabalho como variáveis de ambiente. Isso significa que você poderá criar e compartilhar fluxos de trabalho sem precisar incorporar valores confidenciais diretamente na origem YAML do fluxo de trabalho.
Este trabalho de exemplo demonstra como fazer referência a um segredo existente como uma variável de ambiente e enviá-lo como um parâmetro para um comando de exemplo.
jobs:
example-job:
runs-on: ubuntu-latest
steps:
- name: Retrieve secret
env:
super_secret: ${{ secrets.SUPERSECRET }}
run: |
example-command "$super_secret"
Para obter mais informações, confira "Usar segredos em ações do GitHub".
Criar trabalhos dependentes
Por padrão, os trabalhos do seu fluxo de trabalho são executadas em paralelo e ao mesmo tempo. Se você tiver um trabalho que só precise ser executado após a conclusão de outro, use a palavra-chave needs para criar essa dependência. Se um dos trabalhos falhar, todos os trabalhos dependentes serão ignorados. No entanto, se você precisar que os trabalhos continuem, defina isso usando a instrução condicional if.
Neste exemplo, os trabalhos setup, build e test são executados em série, com build e test dependendo da conclusão bem-sucedida do trabalho anterior:
jobs:
setup:
runs-on: ubuntu-latest
steps:
- run: ./setup_server.sh
build:
needs: setup
runs-on: ubuntu-latest
steps:
- run: ./build_server.sh
test:
needs: build
runs-on: ubuntu-latest
steps:
- run: ./test_server.sh
Para obter mais informações, confira "Usando trabalhos em um fluxo de trabalho".
Usar uma matriz
Uma estratégia de matriz permite que você use variáveis em uma única definição de trabalho para criar automaticamente várias execuções de trabalho baseadas nas combinações das variáveis. Por exemplo, você pode usar uma estratégia de matriz para testar seu código em várias versões de um idioma ou em vários sistemas operacionais. A matriz é criada usando a palavra-chave strategy, que recebe as opções de construção como uma matriz. Por exemplo, essa matriz executará o trabalho várias vezes, usando diferentes versões de Node.js:
jobs:
build:
runs-on: ubuntu-latest
strategy:
matrix:
node: [14, 16]
steps:
- uses: actions/setup-node@v4
with:
node-version: ${{ matrix.node }}
Para obter mais informações, confira "Usando uma matriz para seus trabalhos".
Memorizar dependências
Se os seus trabalhos reutilizam dependências regularmente, considere armazenar em cache esses arquivos para ajudar a melhorar o desempenho. Após a criação do armazenamento em cache, ele fica disponível para todos os fluxos de trabalho no mesmo repositório.
Este exemplo demonstra como armazenar o diretório ~/.npm em cache:
jobs:
example-job:
steps:
- name: Cache node modules
uses: actions/cache@v3
env:
cache-name: cache-node-modules
with:
path: ~/.npm
key: ${{ runner.os }}-build-${{ env.cache-name }}-${{ hashFiles('**/package-lock.json') }}
restore-keys: |
${{ runner.os }}-build-${{ env.cache-name }}-
Para obter mais informações, confira "Memorizar dependências para acelerar os fluxos de trabalho".
Usar bancos de dados e contêineres de serviço
Se o trabalho exigir um banco de dados ou um serviço de cache, use a palavra-chave services para criar um contêiner efêmero para hospedar o serviço. O contêiner resultante ficará disponível para todas as etapas desse trabalho e será removido quando o trabalho for concluído. Este exemplo demonstra como um trabalho pode usar services para criar um contêiner postgres e usar node para se conectar ao serviço.
jobs:
container-job:
runs-on: ubuntu-latest
container: node:10.18-jessie
services:
postgres:
image: postgres
steps:
- name: Check out repository code
uses: actions/checkout@v4
- name: Install dependencies
run: npm ci
- name: Connect to PostgreSQL
run: node client.js
env:
POSTGRES_HOST: postgres
POSTGRES_PORT: 5432
Para obter mais informações, confira "Usando serviços de contêineres".
Usar etiquetas para encaminhar fluxos de trabalho
Se você quiser ter certeza de que um determinado tipo de executor irá processar seu trabalho, você pode usar etiquetas para controlar os locais onde os trabalhos são executados. Você pode atribuir rótulos a um executor auto-hospedado, além do rótulo padrão de self-hosted. Em seguida, você pode consultar esses rótulos em seu fluxo de trabalho YAML, garantindo que o trabalho seja roteado de maneira previsível. Executores hospedados no GitHub têm rótulos predefinidos atribuídos.
Este exemplo mostra como um fluxo de trabalho pode usar etiquetas para especificar o executor obrigatório:
jobs:
example-job:
runs-on: [self-hosted, linux, x64, gpu]
Um fluxo de trabalho só será executado em um executor que tenha todos os rótulos na matriz runs-on. O trabalho irá preferencialmente para um executor auto-hospedado inativo com as etiquetas especificadas. Se não houver nenhum disponível e houver um corredor hospedado em GitHub com os rótulos especificados, o trabalho irá para um executor hospedado em GitHub.
Para saber mais sobre rótulos de executores auto-hospedados, confira "Usar rótulos com os executores auto-hospedados".
Para saber mais sobre os rótulos de executores hospedados no GitHub, confira "Usar executores hospedados no GitHub".
Reutilizar fluxos de trabalho
Você pode chamar um fluxo de trabalho de dentro de outro fluxo de trabalho. Isso permite a reutilização de fluxos de trabalho, evitando duplicação e tornando seus fluxos de trabalho mais fáceis de manter. Para obter mais informações, confira "Reutilizar fluxos de trabalho".
Proteção de segurança para fluxos de trabalho
O GitHub oferece recursos de segurança que você pode usar para aumentar a segurança de seus fluxos de trabalho. Você pode usar os recursos internos do GitHub para garantir que receba notificações sobre vulnerabilidades nas ações que consome ou para automatizar o processo de manter as ações em seus fluxos de trabalho atualizadas. Para obter mais informações, confira "Usar os recursos de segurança do GitHub para proteger seu uso do GitHub Actions".
Usar ambientes
Você pode configurar ambientes com regras e segredos de proteção para controlar a execução de trabalhos em um fluxo de trabalho. Cada trabalho em um fluxo de trabalho pode fazer referência a um único ambiente. Todas as regras de proteção configuradas para o ambiente têm de ser aprovadas antes que um trabalho de referência ao ambiente seja enviado a um executor. Para obter mais informações, confira "Usando ambientes para implantação".